
Hotel search on traditional Online Travel Agencies (OTAs) can be a time-consuming experience, relying on rigid filters that often fail to capture real traveler intent. Large language models are being positioned as a solution, allowing users to describe exactly what they need in natural language while AI handles the search.
But how well do these models actually perform in real-world travel search? Are they providing relevant, bookable recommendations, or are they driving people back to traditional booking sites out of frustration?
We tested several leading AI platforms to see how effectively they process a detailed hotel query. Each model was given the same query and evaluated across three key factors: relevance, accuracy, and comprehensiveness. The results reveal progress among LLMs is uneven, with some offering up convenient features but falling short on recommendation quality, and vice versa.
Test Query
We gave each LLM the same question: “Best Washington, DC hotels for a family on a budget, well-positioned near the Smithsonian museums and national mall from April 4 to 6, 2025”
Evaluation Criteria
To rate the responses, we’ll look at a couple key factors:
- Relevance – How well do the hotel recommendations match the question?
- Accuracy – How correct is the information presented?
- Comprehensiveness – How detailed and useful is the provided hotel data?
We’ll rate each category on a scale of 1-5 for a total of 15 possible points.
A few caveats: Of course, a single query isn’t enough to fully rate these models’ capabilities in hotel search. These companies are likely running all kinds of tests, results could change, and the specific models compared across each serve slightly different purposes. So there’s no perfect apples-to-apples comparison. So, try it yourself! Do you agree with our scores?
Let’s start the AI engines!
Google Gemini
Given Google’s vast travel data and existing hotel search products, you could argue they have an unfair advantage. But let’s put it to the test and confirm how they stack up.
Here’s Gemini’s response to the question (model Flash 2.0):
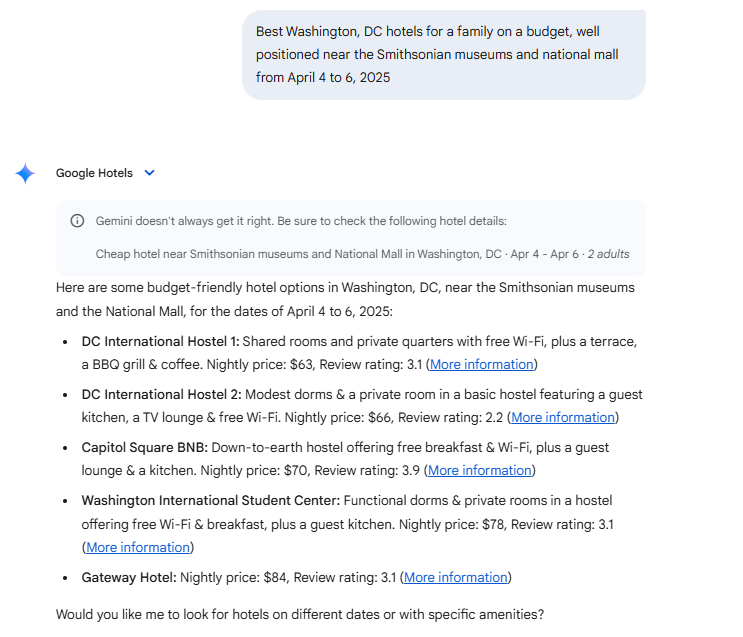
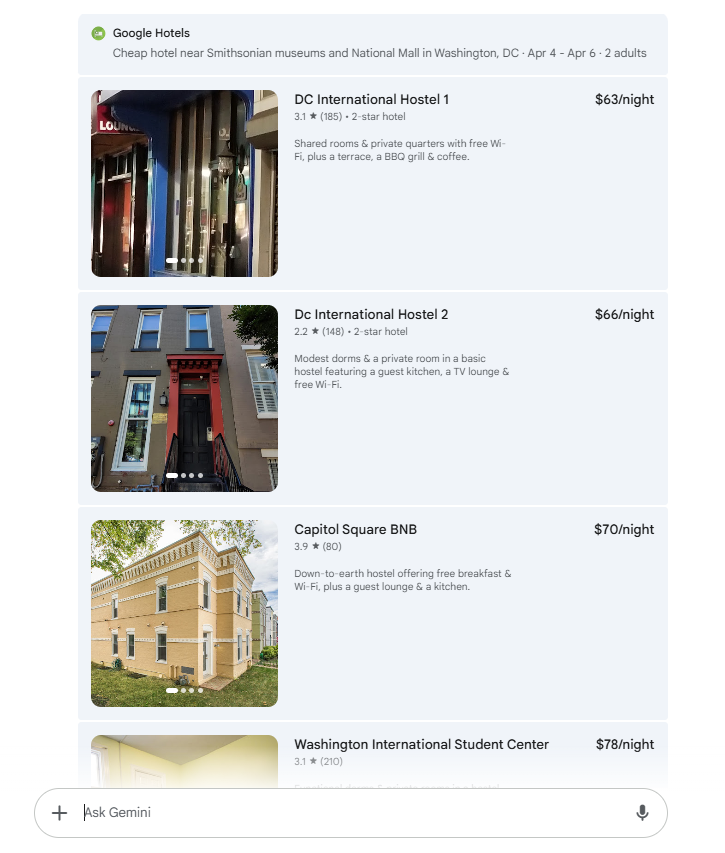
So, how did Gemini do? Let’s rate it across our criteria:
Relevance: Gemini did a great job finding budget friendly options, but how many families are comfortable with a dorm room in a hostel? This list is pretty far from what most families visiting DC will be looking for. Furthermore, The Washington International Student Center and Gateway hotel are not anywhere close to the attractions requested. Score: 1/5
Accuracy: While the data (prices, photos, price, user ratings) about each hotel is accurate, I can’t give Gemini a full score because the hotels are not family friendly. Score: 3/5
Comprehensiveness: Some key data needed to inform my decision is here, however it’s missing distances/map and amenities relevant to families. Score: 3/5
TOTAL SCORE FOR GEMINI: 7/15
ChatGPT
As the most widely used language model, OpenAI’s ChatGPT also has a lot to live up to. Can it compete with Google’s vast travel data and provide a better experience? Let’s put it to the test.
Here’s ChatGPT’s response to the question (model 4o w/ search):
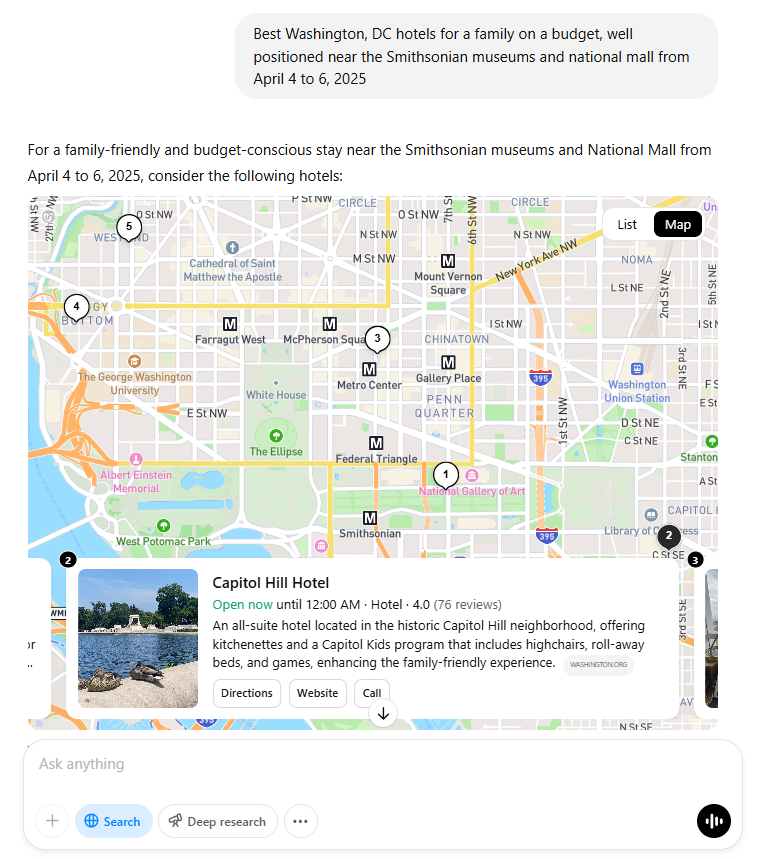
Relevance: All the hotels recommended by ChatGPT explain exactly how they’re great for families. Additionally, I can easily see how far they are from the key attractions I asked about. Spot checking a few prices, most these hotels look moderately priced and some fairly expensive (up to $500/night), which could turn budget conscious families off. Some of the recommendations are a little further afield than they need to be. Score: 3/5
Accuracy: While the hotel name and location information is accurate, the user review ratings and hours do not appear to always correspond exactly to other online sources. I would need to take these recommendations and do some more research elsewhere before booking to confirm the user reviews. Score: 3/5
Comprehensiveness: The location information with direct links to the websites are great, though I miss Gemini’s deep links directly to the dates I asked for. Prices are missing, and user ratings are not to be trusted, while the photos are also quite small. Score: 2/5
TOTAL SCORE FOR CHATGPT: 8/15
Claude
Anthropic’s Claude has gained a cult following among programmers for coding tasks, but how does it fair for a hotel search? Unlike Gemini and ChatGPT, Claude does not yet have web search capabilities, giving it a disadvantage for real-time information. Let’s put it to the test.
Here’s Claude’s response to the question (model 3.7 Sonnet)
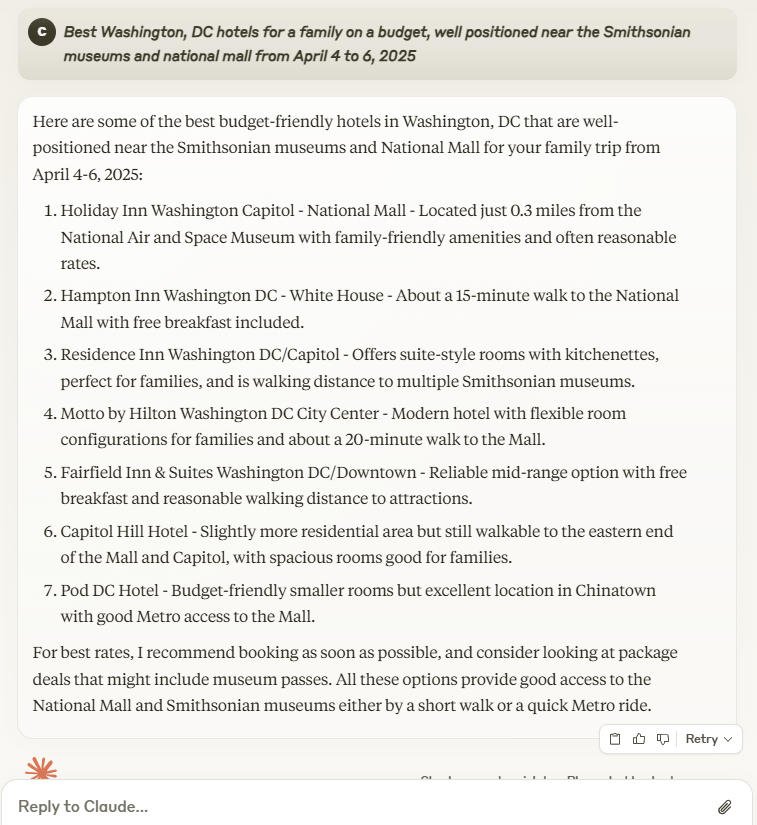
Relevance: A very solid list of budget friendly options for families. No complaints with these recommendations. Score: 5/5
Accuracy: While only limited information is provided for each hotel, the accuracy appears pretty good, including the proximity estimates which are important. Score: 4/5
Comprehensiveness: Claude doesn’t try to get fancy with maps, data points or photos, but does highlight a few key important things for each hotel. Extra research is required to make a decision. Score: 2/5
TOTAL SCORE FOR CLAUDE: 11/15
Grok
A newer language model by X.ai, Grok has quickly gained a following among die hard enthusiasts.
Here is a sample of the results, abbreviated a bit:
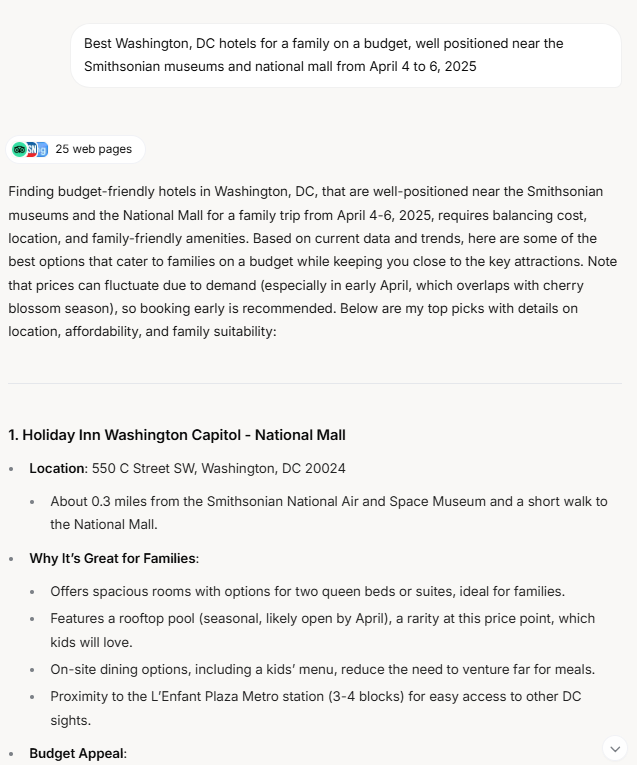

Relevance: Grok provides a mix of budget and mid range options that could be appropriate to families, all within a reasonable distance of the attractions. Some were pricier than what a budget-conscious family might expect. Score: 4/5
Accuracy: Accuracy needs improvement in places. One of its recommendations, Hotel Harrington, closed down in December 2023, over a year ago. Its price estimate for for at least one hotel was pretty far off for the dates I asked for. But it also offers plenty of accurate details as well, in more depth than other models. Score: 3/5
Comprehensiveness: For those seeking extra context, Grok’s response had plenty of detail, answering key questions about family friendliness, and budget appeal. But it’s hard to give a full 5/5 as it’s missing images, maps and isn’t always accurate. Score: 4/5
TOTAL SCORE FOR GROK: 11/15
The winners: Claude & Grok
| AI Model | Relevance | Accuracy | Comprehensiveness | Total Score (15) |
|---|---|---|---|---|
| Google Gemini | 1/5 | 3/5 | 3/5 | 7/15 |
| ChatGPT | 3/5 | 3/5 | 2/5 | 8/15 |
| Claude | 5/5 | 4/5 | 2/5 | 11/15 |
| Grok | 4/5 | 3/5 | 4/5 | 11/15 |
Claude and Grok stood out by delivering the most relevant budget-friendly hotel options within close proximity to the requested attractions. While Grok lost points for some accuracy issues, its responses were detailed and directly addressed the original question, making up for some shortcomings.
Gemini, despite leveraging Google’s vast travel data, missed the mark by recommending hotels that were neither family-friendly nor well-located. ChatGPT performed better, offering useful family-oriented details and a map, but some recommendations were less budget-conscious, and key hotel details were inaccurate.
The key takeaway for AI companies? Before layering on advanced features like real-time pricing and date-driven links, ensure the fundamentals are solid. Accuracy, relevance, and practical usability should come first. No traveler benefits from precise pricing on the wrong hotels.